When you want to automate or orchestrate your cloud(s) you have at least a few choices. The command line tools and scripting is the very basic one and rather a very "old-fashioned" way. Probably the best choice would be a mix of automation or orchestration tool and the cloud management software like BMC Cloud Lifecycle Management, VMware vRealize or yet another one (e.g. Microsoft System Center, Red Hat CloudForms, etc.). Anyway, most vendors of cloud computing software (or services) provide a web service interface for the solution and it usually covers all or almost all the levels of the cloud management. The most of the web services are
RESTful or REST-based.
In this post I would like to present how to start using the web services. Just for the example I will not use any high-level cloud management software (which you may not have or even are not going to have). I am going to use the cloud platform directly, but this particular platform has also capabilities of orchestration, so some higher level is already built-in there.
As the title says, let's have a special look at OpenStack and Control-M (as the automation tool).
Control-M already has got a module for clouds. It is called Control-M for Cloud and does not require much knowledge about the web services. Unfortunately the current version (v7) directly supports only VMware vSphere, VMware vCenter (both use WSDL/SOAP) and Amazon EC2 (by the way -
EC2 SOAP is deprecated now and will not be supported after 2014). However...
...Control-M has got also Control-M for Web Services module (plug-in). Since the version 8 of the module, it supports not only WSDL/SOAP (like before this version) but also REST-based protocols, so the module may be used with many other cloud computing products and services (VMware vRealize/vCloud, "non-SOAP" AWS, Microsoft, OpenStack, Xen, etc.).
OpenStack consists of some components, about of 10 in the current version. Most of the components have the REST(ful) service interface. So, we can use all of them within our automation tasks. OpenStack includes also a special component for orchestration - Heat. If you are familiar with Amazon Web Services CloudFormation Query you may use your knowledge (and the previous work) with Heat, because the OpenStack component provides the CloudFormatio
n-compatible interface as well (in addition to the native one).
Heat works with templates which have been named HOT :-) (Heat Orchestration Templates). The AWS CloudFormation templates can be used too. If we use the Heat REST service, our template may be provided through any external source (URL) or within the HTTP(S) web service request.
The Heat service can be used like other web services of OpenStack. So, our tasks and processes can evolve from the automation form to the orchestration without much effort in this particular area.
For our example let's use very basic and simple template as below:
heat_template_version: 2013-05-23
description: Simple sample template
resources:
my_instance:
type: OS::Nova::Server
properties:
name: TestInstance
key_name: rooty
image: RHEL 7 Base
flavor: RHEL.Base
networks:
- network: int-net
The templates are formatted usually in YAML (the data serialization format) but JSON (JavaScript Object Notation) format is also supported. With Control-M we will use the JSON. The full HTTP/REST request body will look like below:
{
"stack_name": "TestStack",
"template": {
"heat_template_version": "2013-05-23",
"description": "Simple sample template",
"resources": {
"my_instance": {
"type": "OS::Nova::Server",
"properties": {
"name": "TestInstance",
"key_name": "rooty",
"image": "RHEL 7 Base",
"flavor": "RHEL.Base",
"networks": [ { "network": "int-net" } ]
}
}
}
}
}
This particular template makes a simple stack which contains just one resource - the virtual machine instance with Red Hat Enterprise Linux in.
HOT templates have many features and can be very useful. If you are beginner here, I would recommend reading the
Heat Template Guide. Full description of the template format can be found in the
HOT specification.
Before we can use the Heat service or any other of the OpenStack, we have to log in to the cloud platform and receive the authentication token. The OpenStack component for identity (named Keystone) is responsible for this. It may be integrated with external identity providers/services, but in our case we will use the user/password authentication.
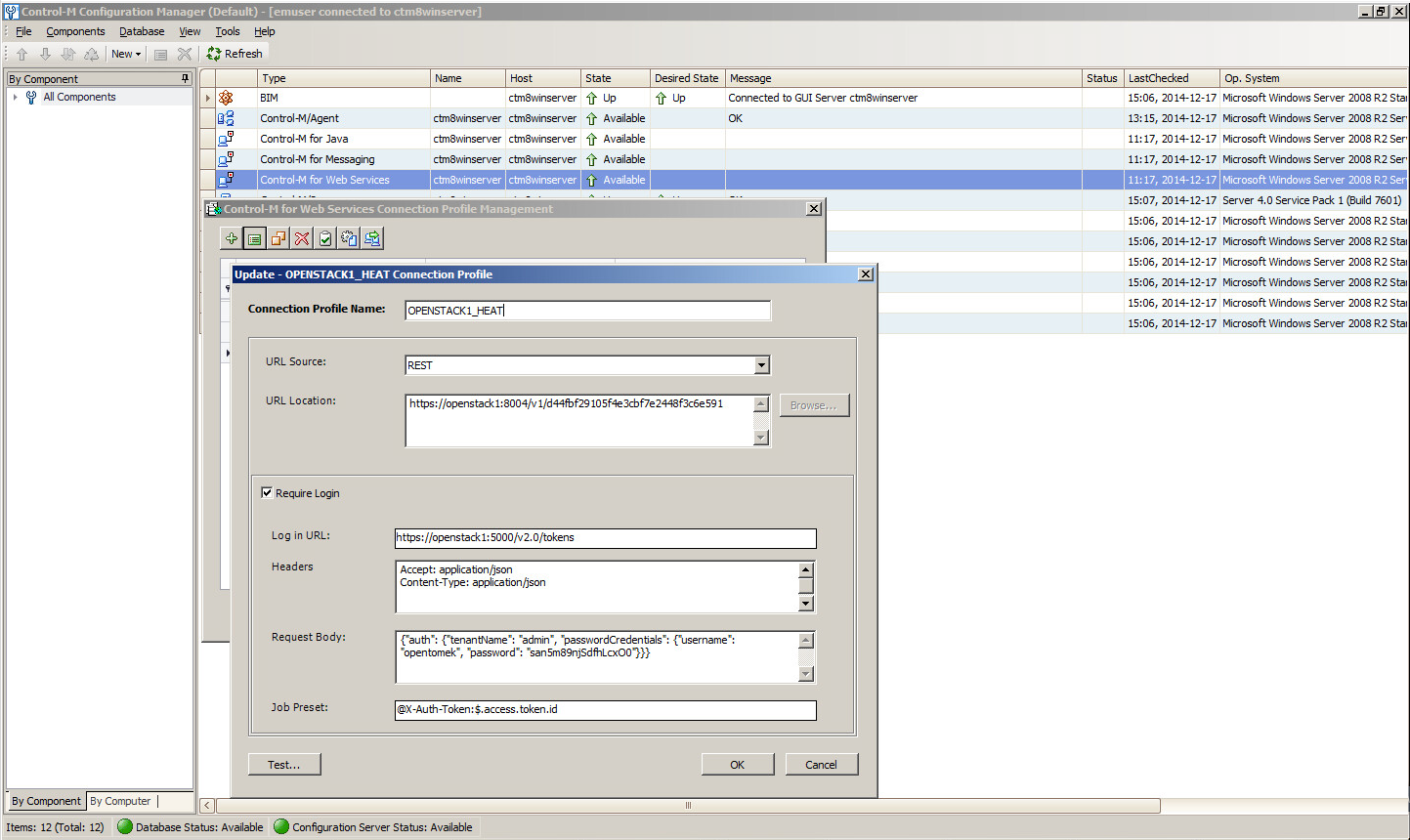
It's nice that Control-M for Web Services supports the REST authentication process by "out-of-the-box". Like usually, we may define all the details in the Control-M Configuration Manager.
In our case I use the Heat (Orchestration) service to orchestrate (to deploy and remove the stack) and the Nova (Compute) service to automate only (to stop and start the virtual machine), so the two web service connection profiles have to be defined:
They may use the same or different OpenStack user accounts. When we have the profiles, we can start working on the Control-M jobs and then we should not forget about the special HTTP status codes of the OpenStack REST actions. If we have forgotten to handle the codes, our job can fail when the result code is fine for our action.
So, there is the sample job for the orchestration (the deployment of the simple stack):
The next job removes the stack (so the machine) if it is necessary:
But when we have the machine running yet, sometimes we may need to stop it only for a while or to do something else with this machine. OpenStack uses special IDs to differentiate between the instances, so if we know the machine name only, we have to get the ID before we can do the action.
The job to get the ID:
The next one which can stop the machine:
After some time we may need to run the machine again:
That's all for now. Just in case I have made you ;-) interested in the OpenStack REST services, they are described in the
OpenStack API Complete Reference.
Anyhow, I hope you have found this post useful.
As usually, any substantive comments, questions, requests or errata are very welcome.
Something to read and/or try: